












Was steckt hinter Asynchronous Compute?
Ich habe ja bereits vor über 5 Jahren dazu eine längere Ausführung geschrieben, möchte das Ganze aber trotzdem noch einmal ein wenig auffrischen, weil es wichtig ist. Worum geht es hier genau? Viele der In-Game-Effekte wie Schattenwurf, Beleuchtung, künstliche Intelligenz, Physik und Linseneffekte erfordern oft mehrere Berechnungsschritte, bevor überhaupt erst einmal feststeht, was von der Grafikhardware einer GPU auf den Bildschirm gerendert wird. Noch in DirectX 11 mussten diese Schritte sequentiell, also hintereinander ablaufen.
Schritt für Schritt folgte die Grafikkarte nun dem Prozess der API, um etwas von Anfang bis Ende zu rendern. Und man kennt es ja auch von einem Stau auf einer Autobahn: jede Verzögerung in einem frühen Stadium der Staubildung würde dann als Folge eine immer größer werdende Welle von Verzögerungen in der Zukunft bedeuten. Diese Verzögerungen in der Pipeline werden auch etwas flapsig als “Bubbles” bezeichnet und repräsentieren dann einen gewissen Moment, in dem ein Teil der GPU-Hardware pausieren muss, um auf neue Anweisungen zu warten.
Die nachfolgende Grafik zeigt die visuelle Darstellung des DirectX-11-Threading. Alle Grafik-, Speicher- und Rechenoperationen werden in einer langen Abfolge der Abarbeitung (“Pipeline”) zusammengefasst, die extrem anfällig für Verzögerungen ist:

Diese sogenannten “Pipeline-Bubbles” passieren natürlich ständig und auch auf jeder Grafikkarte, denn kein Spiel der Welt kann wirklich die gesamte Leistung oder Hardware, die eine GPU zu bieten hat, perfekt ausnutzen. Und kein Spiel kann zudem konsequent vermeiden, dass solche Blasen entstehen, wenn der Benutzer sich frei in der Spielewelt bewegt und agiert. Und jetzt kommt der Kniff mit dem “Asynchronous Compte”. Was wäre, wenn man diese Blasen anstelle zu warten mit anderen Aufgaben füllen könnte, um die Hardware besser auszunutzen, damit weniger Rechenleistung brach liegt?
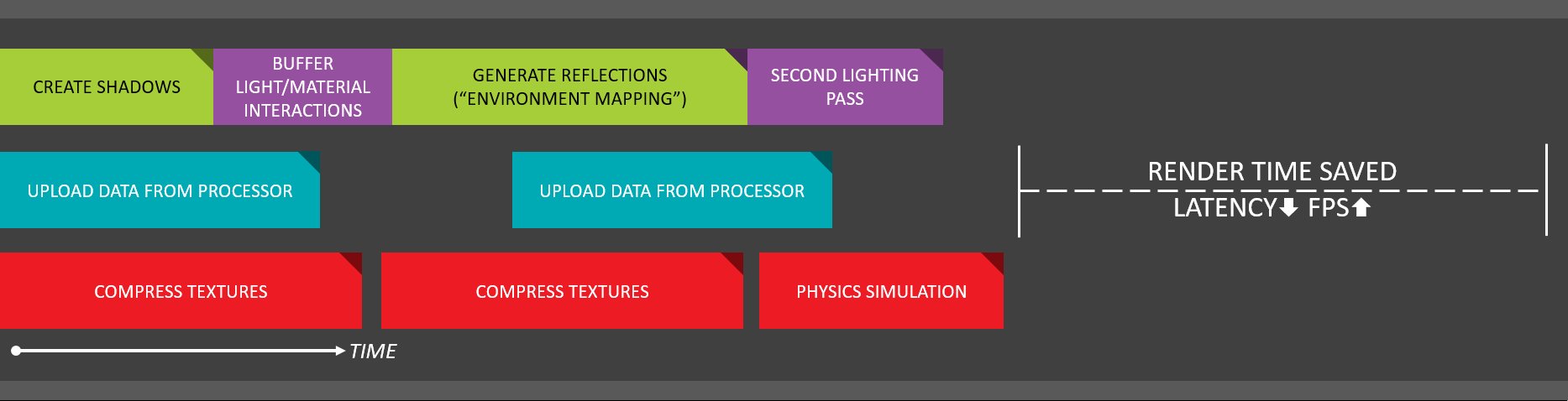
Wenn zum Beispiel beim Rendern komplexer Beleuchtungen eine Rendering-Blase entsteht, könnte man in der Zwischenzeit ja zum Beispiel die KI berechnen lassen. Man kann also mehrere Dinge parallel erledigen oder noch anstehende, passende Aufgaben einfach vorziehen. Die nächste Grafik ist die visuelle Darstellung des Ablaufs der asynchronen Berechnungen unter DirectX 12. Die Grafik-, Speicher- und Rechenoperationen werden in unabhängige Aufgabenpakete entkoppelt, die dann sogar parallel ausgeführt werden können:
Zusammenfassung und Fazit
Als Folge der sinkenden Auflösung steigt natürlich die Anzahl der gerenderten Einzelbilder (“Frames”) und die Latenz sinkt im Gegenzug. Was aber hat das nun mit der CPU und dem Limit durch diese zu tun? Viele Dinge laufen ja auch über CPU und allein die Anzahl der Drawcalls steigt mit sinkender Auflösung dramatisch. Die CPU muss stets liefern, damit die Grafikhardware auch immer optimal ausgelastet ist. Hier aber scheint die Säge bei NVIDIAs Treibern ein wenig zu klemmen. Ich würde nicht so weit gehen und vermuten, dass NVIDIA immer noch Probleme mit dem asynchronen Abarbeiten der Pipelines hat, aber optimal ist das Ganze wohl immer noch nicht. Vor allem, wenn Engines auf AMDs Hardware hin optimiert wurden (z.B. das Single Pass Downsampling in HZD)

Die Abhängigkeit von Spiel und Engine fordert an dieser Stelle eigentlich eine genauere Untersuchung dieser Problematik geradezu heraus, allein mir fehlt als Einzelkämpfer mit derzeit sogar zwei noch anstehenden Launches ein wenig die Zeit dafür. Ich würde einen generelle Performance-Verlust der GeForce-Treiber bei niedrigeren Auflösungen durch einen pauschal deklarierten “Overhead” eigentlich ausschließen wollen, denn auch wenn die Programmierer beider Teams auch gern einmal etwas schusselig sind, so brutal daneben liegt man bei NVIDIA mit Sicherheit nicht.
Egal, ob Horizon Zero Dawn oder Watch Dogs Legion, immer dann, wenn bei der GeForce die FPS einbrachen (vor allem bei den Messungen mit nur 2 Kernen), waren das langsamere Aufploppen von Inhalten, das verzögerte Laden der Texturen oder Fehler bei Beleuchtung und Schatten auf der Radeon weniger schlimm als bei der GeForce. Auch das werte ich als Indikator dafür, dass hier einfach die Pipeline dicht war (Bubbles) und das Multi-Threading auf der GPU nicht wirklich optimal ablief. Dafür sprechen ja auch die immer gleichen prozentualen Abstände zwischen beiden Karten bei der Erhöhung der Kernzahl und der Verringerung des CPU-Limits (siehe Seite Zwei). Denn ich sehe das Problem eher weniger bei der CPU, sondern der Abarbeitung der Pipelines auf der GPU. Eine limitierende CPU macht den Vorgang nur deutlicher, ist aber nicht der eigentliche Grund.
Es muss natürlich handfeste Gründe haben, warum dies alles so passiert, Software- oder vielleicht sogar Hardware-bedingt. Dann aber nicht irgendwie pauschal samt generell mieser Treiber, sondern sehr speziell und eingrenzbar, vielleicht sogar auch noch Plattform-bedingt bei älteren Systemen als Summe von negativen Faktoren. Denn wir haben ja auch gesehen, dass man bei Tests auf ein und derselben, aktuellen Plattform mit PCIe 4.0 nicht derart große Unterschiede finden kann, wie es bei den Kollegen der Fall war.
Aktuell kann man als Fazit immerhin mitnehmen, dass die Grafikhardware zum Rest des Systems und natürlich auch der genutzten Bildschirmauflösung passen sollte und man mit solch potenten Karten wie der GeForce RTX 3080 oder RTX 3090 auf (älteren) Systemen mit eher schwachen CPUs in niedrigen Auflösungen sowieso keinen Blumentopf dazugewinnt. Egal on nun mit oder ohne Limits. Es sei denn, man will nebenher noch kryptisches Schwarzgeld schürfen. Aber das ist dann schon nicht mehr mein Problem.


















143 Antworten
Kommentar
Lade neue Kommentare
Urgestein
1
Urgestein
1
Veteran
1
Veteran
Urgestein
Urgestein
1
Veteran
Urgestein
Veteran
Urgestein
Veteran
Moderator
1
Veteran
Alle Kommentare lesen unter igor´sLAB Community →