













Über den Rahmen dessen hinaus, was Volta betrifft und wohl das vielversprechendste Kapitel in der ganzen Turing-Story darstellt, ist der RT-Kern, der an der Unterseite jedes SM in TU102 verankert ist. Die RT-Kerne von Nvidia sind im Wesentlichen reine Beschleuniger mit fest „vorverdrahteter“ Funktion für die Auswertung von Quer- und Dreiecksschnitten der Bounding Volume Hierarchy (BVH). Beide Operationen sind für den Raytracing-Algorithmus unerlässlich.
Kurz gesagt, diese BVH bilden Boxen mit Geometrieinhalten in einer bestimmten Szene. Diese Boxen helfen, die Position von Dreiecken einzugrenzen, die Strahlen durch eine Baumstruktur schneiden. Jedes Mal, wenn sich ein Dreieck in einer Box befindet, wird diese in mehrere weitere Boxen unterteilt, bis die letzte Box in Dreiecke unterteilt werden kann. Ohne BVHs wäre ein Algorithmus gezwungen, die gesamte Szene zu durchsuchen, indem er Tonnen von Zyklen verheizt, die jedes einzelne Dreieck auf eine mögliche Kreuzung testen.

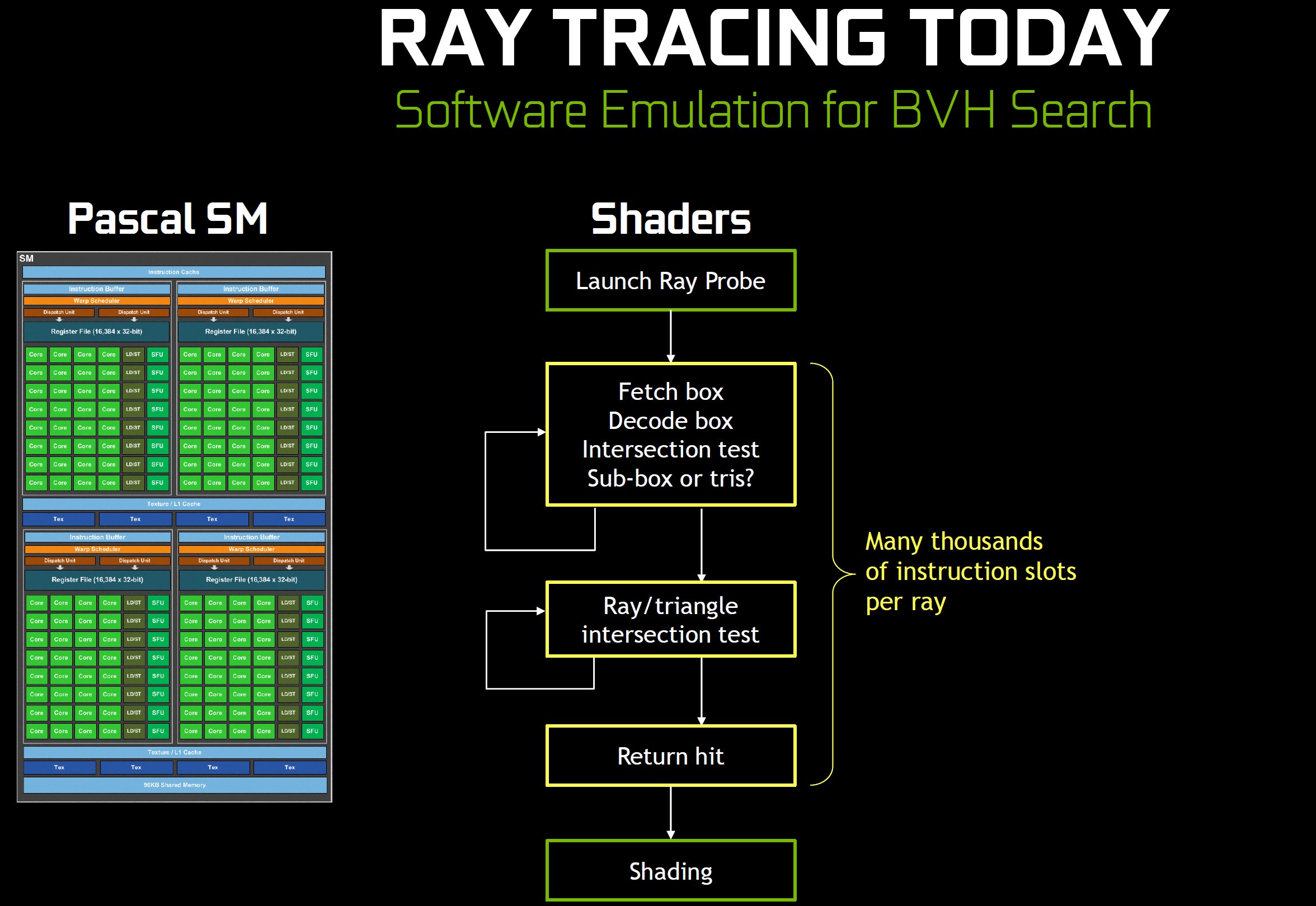
Die Ausführung dieses Algorithmus ist mittlerweile mit den Microsoft D3D12 Raytracing Fallback Layer APIs möglich, die mit Hilfe von Compute Shadern DirectX Raytracing auf Geräten auch ohne native Unterstützung emulieren (und auf DXR umleiten, wenn die Treiberunterstützung erkannt wird). Auf einer Pascal-basierten GPU zum Beispiel erfolgt der BVH-Scan auf programmierbaren Kernen, die jede Box holen, dekodieren, auf Schnittpunkte testen und feststellen, ob sich eine weitere, untergerordnete Box oder Dreiecke im Inneren befinden.

Der Prozess wiederholt sich, bis Dreiecke gefunden werden, an deren Stelle sie auf Schnittpunkte mit dem Strahl getestet werden. Wie man sich vorstellen kann, ist dieser Vorgang sehr hardwaremordend in der Ausführung als reine Software-Emulation, so dass ein reibungsloser Ablauf des Echtzeit-Raytracing auf den heutigen Grafikprozessoren fast schon verhindert wird.
Durch die Erstellung von derartigen Beschleunigern mit fester Funktion für die Kreuzungsschritte zwischen Box und Dreieck wirft die SM einen Strahl mit einem Ray-Generation-Shader in die Szene und übergibt diese Struktur an den RT-Kern. Alle Schnittpunktauswertungen erfolgen dadurch natürlich viel schneller und die anderen Ressourcen der SM werden für das Shading freigegeben, genau wie bei einer traditionellen Rasterung.

Laut Nvidia kann eine GeForce GTX 1080 Ti mit ihren CUDA-Kernen, die 11,3 FP32-TFLOPs leisten, etwa 1,1 Milliarden Strahlen pro Sekunde in Software verarbeiten. Im Vergleich dazu kann die GeForce RTX 2080 Ti mit seinen 68 RT-Kernen etwa 10 Milliarden Strahlen pro Sekunde verarbeiten. Es ist wichtig zu beachten, dass keine dieser Zahlen auf berechneten Spitzenwerten basiert. Vielmehr nahm Nvidia den geometrischen Mittelwert der Ergebnisse aus mehreren Workloads, um sich auf den Wert von “10+ Gigarays” festzulegen.
Doch Ray Tracing ein an sich sehr weit gesteckter Begriff, denn allein nur die Verfolgung eines Strahles sagt noch nicht viel aus. Wichtiger ist dann schon, was man mit Hilfe dieser Funktionen gleich noch mit umsetzen kann. denn die so gewonnenen Informationen lassen sich sehr vielseitig verwenden, um Dinge wie AO, Reflektionen, Global Illumination uvm. zu verbessern bzw. überhaupt erst möglich zu machen.

- 1 - Einführung und Vorstellung
- 2 - TU102 + GeForce RTX 2080 Ti
- 3 - TU104 + GeForce RTX 2080
- 4 - TU106 + GeForce RTX 2070
- 5 - Performance-Anstieg für bestehende Anwendungen
- 6 - Tensor-Kerne und DLSS
- 7 - Ray Tracing in Echtzeit
- 8 - NVLink: als Brücke wohin?
- 9 - RTX-OPs: wir rechnen nach
- 10 - Shading-Verbesserungen
- 11 - Anschlüsse und Video
- 12 - 1-Klick-Übertaktung
- 13 - Tschüss, Gebläselüfter!
- 14 - Zusammenfassung und Fazit

















Kommentieren